 Boost
C++ Libraries
Boost
C++ Libraries
...one of the most highly
regarded and expertly designed C++ library projects in the
world.
— Herb Sutter and Andrei
Alexandrescu, C++
Coding Standards
Boost
C++ Libraries
...one of the most highly
regarded and expertly designed C++ library projects in the
world.
— Herb Sutter and Andrei
Alexandrescu, C++
Coding Standards
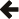


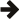
This section assumes that you have read all other sections, the most of important of which being tutorial, std::set theory and the reference, and that you have tested the library. A lot of effort was invested in making the interface as intuitive and clean as possible. If you understand, and hopefully like, the interface of this library, it will be a lot easier to read this rationale. The following section is little more than a rationale. This library was coded in the context of the Google SoC 2006 and the student and mentor were in different continents. A great deal of email flowed between Joaquin and Matias. The juiciest parts of the conversations where extracted and rearranged here.
![[Note]](../../../../../doc/html/images/note.png) |
Note |
|---|---|
To browse the code, you can use the Bimap Complete Reference, a doxygen-powered document targeted at developers. |
The initial explanation includes few features. This section aims to describe the general design of the library and excludes details of those features that are of lesser importance; these features will be introduced later.
The design of the library is divided into two parts. The first is the construction
of a relation class. This will be the object stored and
managed by the multi_index_container core. The idea is
to make this class as easy as possible to use, while making it efficient
in terms of memory and access time. This is a cornerstone in the design of
Boost.Bimap and, as you will see in this
rationale, the rest of the design follows easily.
The following interface is necessary for the relation
class:
typedef -unspecified- TA; typedef -unspecified- TB; TA a, ai; TB b, bi; typedef relation< TA, TB > rel; STATIC_ASSERT( is_same< rel::left_type , TA >::value ); STATIC_ASSERT( is_same< rel::right_type, TB >::value ); rel r(ai,bi); assert( r.left == ai && r.right == bi ); r.left = a; r.right = b; assert( r.left == a && r.right == b ); typedef pair_type_by< member_at::left , rel >::type pba_type; STATIC_ASSERT( is_same< pba_type::first_type , TA >::value ); STATIC_ASSERT( is_same< pba_type::second_type, TB >::value ); typedef pair_type_by< member_at::right, rel >::type pbb_type; STATIC_ASSERT( is_same< pbb_type::first_type , TB >::value ); STATIC_ASSERT( is_same< pbb_type::second_type, TA >::value ); pba_type pba = pair_by< member_at::left >(r); assert( pba.first == r.left && pba.second == r.right ); pbb_type pbb = pair_by< member_at::right >(r); assert( pbb.first == r.right && pbb.second == r.left );
Although this seems straightforward, as will be seen later, it is the most difficult code hack of the library. It is indeed very easy if we relax some of the efficiency constraints. For example, it is trivial if we allow a relation to have greater size than the the sum of those of its components. It is equally simple if access speed is not important. One of the first decisions made about Boost.Bimap was, however, that, in order to be useful, it had to achieve zero overhead over the wrapped Boost.MultiIndex container. Finally, there is another constraint that can be relaxed: conformance to C++ standards, but this is quite unacceptable. Let us now suppose that we have coded this class, and it conforms to what was required.
The second part is based on this relation class. We can
now view the data in any of three ways: pair<A,B>,
relation<A,B> and pair<B,A>.
Suppose that our bimap supports only one-to-one relations. (Other relation
types are considered additional features in this design.) The proposed interface
is very simple, and it is based heavily on the concepts of the STL. Given
a bimap<A,B> bm:
bm.left is signature-compatible with a
std::map<A,B>
bm.right is signature-compatible with a
std::map<B,A>
bm is signature-compatible
with a std::set<relation<A,B> >
This interface is easily learned by users who have a STL background, as well as being simple and powerful. This is the general design.
This section explains the details of the actual relation
class implementation.
The first thing that we can imagine is the use of an union.
Regrettably, the current C++ standard only allows unions of POD types. For
the views, we can try a wrapper around a relation<A,B> that
has two references named first and second that bind to A
and B, or to B and A.
relation<TA,TB> r; const_reference_pair<A,B> pba(r); const_reference_pair<B,A> pbb(r);
It is not difficult to code the relation class using this, but two references
are initialized at every access and using of pba.first
will be slower in most compilers than using r.left directly
. There is another hidden drawback of using this scheme: it is not iterator-friendly,
since the map views iterators must be degraded to Read Write
instead of LValue. This will be explained later.
At first, this seems to be the best we can do with the current C++ standard. However there is a solution to this problem that does not conform very well to C++ standards but does achieve zero overhead in terms of access time and memory, and additionally allows the view iterators to be upgraded to LValue again.
In order to use this, the compiler must conform to a layout-compatibility clause that is not currently in the standard but is very natural. The additional clause imposes that if we have two classes:
struct class_a_b { Type1 name_a; Type2 name_b; }; struct class_b_a { Type1 name_b; Type2 name_a; };
then the storage layout of class_a_b is equal to the storage
layout of class_b_a. If you are surprised to learn that
this does not hold in a standards-compliant C++ compiler, welcome to the
club. It is the natural way to implement it from the point of view of the
compiler's vendor and is very useful for the developer. Maybe it will be
included in the standard some day. Every current compiler conforms to this.
If we are able to count on this, then we can implement an idiom called mutant.
The idea is to provide a secure wrapper around reinterpret_cast.
A class can declare that it can be viewed using different view classes that
are storage-compatible with it. Then we use the free function mutate<view>(mutant)
to get the view. The mutate
function checks at compile time that the requested view is declared in the
mutant views list. We implement a class name structured_pair
that is signature-compatible with a std::pair,
while the storage layout is configured with a third template parameter. Two
instances of this template class will provide the views of the relation.
The thing is that if we want to be standards-compliant, we cannot use this approach. It is very annoying not to be able to use something that we know will work with every compiler and that is far better than alternatives. So -- and this is an important decision -- we have to find a way to use it and still make the library standards-compliant.
The idea is very simple. We code both approaches: the const_reference_pair-based and the mutant-based, and use the mutant approach if the compiler is compliant with our new layout-compatible clause. If the compiler really messes things up, we degrade the performance of the bimap a little. The only drawback here is that, while the mutant approach allows to make LValue iterators, we have to degrade them to Read Write in both cases, because we require that the same code be compilable by any standards-compliant compiler.
|
Note |
|---|---|
Testing this approach in all the supported compilers indicated that the mutant idiom was always supported. The strictly compliant version was removed from the code because it was never used. |
The core of bimap will be obviously a multi_index_container.
The basic idea to tackle the implementation of the bimap class is to use
iterator_adaptor to convert the iterators from Boost.MultiIndex
to the std::map and std::set behaviour.
The map_view and the set_view can be implemented directly using
this new transformed iterators and a wrapper around each index of the core
container. However, there is a hidden idiom here, that, once coded, will
be very useful for other parts of this library and for Boost.MRU library.
Following the ideas from iterator_adaptor,
Boost.Bimap views are implemented using a container_adaptor.
There are several template classes (for example map_adaptor
and set_adaptor) that take
a std::map signature-conformant class and new
iterators, and adapt the container so it now uses this iterators instead
of the originals. For example, if you have a std::set<int*>,
you can build other container that behaves exactly as a std::set<int> using
set_adaptor and iterator_adaptor.
The combined use of this two tools is very powerful. A container_adaptor
can take classes that do not fulfil all the requirements of the adapted container.
The new container must define these missing functions.