Boost
C++ Libraries
Boost
C++ Libraries
...one of the most highly
regarded and expertly designed C++ library projects in the
world.
— Herb Sutter and Andrei
Alexandrescu, C++
Coding Standards
Boost
C++ Libraries
...one of the most highly
regarded and expertly designed C++ library projects in the
world.
— Herb Sutter and Andrei
Alexandrescu, C++
Coding Standards


Boost Spirit is an object-oriented, recursive-descent parser and output generation library for C++. It allows you to write grammars and format descriptions using a format similar to Extended Backus Naur Form (EBNF)[2] directly in C++. These inline grammar specifications can mix freely with other C++ code and, thanks to the generative power of C++ templates, are immediately executable. In retrospect, conventional compiler-compilers or parser-generators have to perform an additional translation step from the source EBNF code to C or C++ code.
The syntax and semantics of the libraries' API directly form domain-specific embedded languages (DSEL). In fact, Spirit exposes 3 different DSELs to the user:
Since the target input grammars and output formats are written entirely in C++ we do not need any separate tools to compile, preprocess or integrate those into the build process. Spirit allows seamless integration of the parsing and output generation process with other C++ code. This often allows for simpler and more efficient code.
Both the created parsers and generators are fully attributed, which allows you to easily build and handle hierarchical data structures in memory. These data structures resemble the structure of the input data and can directly be used to generate arbitrarily-formatted output.
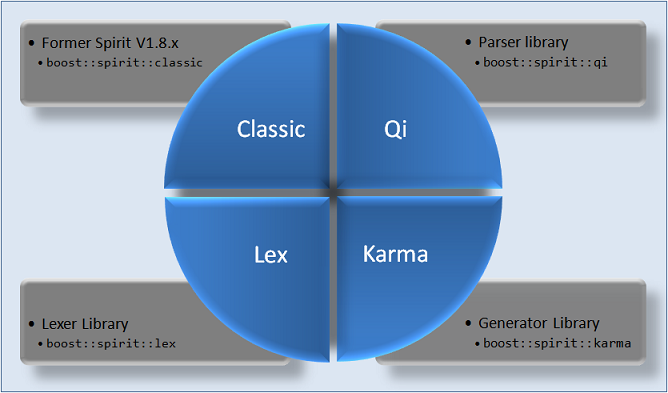
The figure below depicts the overall structure of the Boost Spirit library. The library consists of 4 major parts:
The three components, Spirit.Qi, Spirit.Karma and Spirit.Lex, are designed to be used either standalone, or together. The general methodology is to use the token sequence generated by Spirit.Lex as the input for a parser generated by Spirit.Qi. On the opposite side of the equation, the hierarchical data structures generated by Spirit.Qi are used for the output generators created using Spirit.Karma. However, there is nothing to stop you from using any of these components all by themselves.
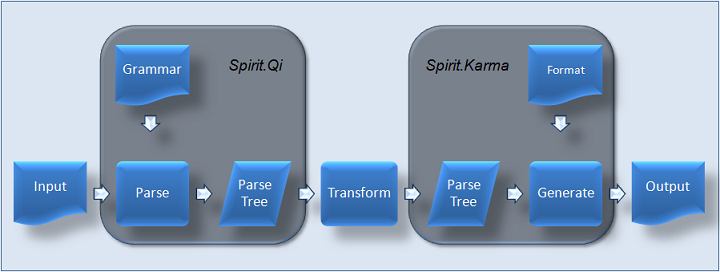
The figure below shows the typical data flow of some input being converted to some internal representation. After some (optional) transformation these data are converted back into some different, external representation. The picture highlights Spirit's place in this data transformation flow.
Figure 2. The place of Spirit.Qi and Spirit.Karma in a data transformation flow of a typical application
Spirit.Qi is Spirit's sublibrary dealing with generating parsers based on a given target grammar (essentially a format description of the input data to read).
A simple EBNF grammar snippet:
group ::= '(' expression ')' factor ::= integer | group term ::= factor (('*' factor) | ('/' factor))* expression ::= term (('+' term) | ('-' term))*
is approximated using facilities of Spirit's Qi sublibrary as seen in this code snippet:
group = '(' >> expression >> ')'; factor = integer | group; term = factor >> *(('*' >> factor) | ('/' >> factor)); expression = term >> *(('+' >> term) | ('-' >> term));
Through the magic of expression templates, this is perfectly valid and executable
C++ code. The production rule expression
is, in fact, an object that has a member function parse
that does the work given a source code written in the grammar that we have
just declared. Yes, it's a calculator. We shall simplify for now by skipping
the type declarations and the definition of the rule integer
invoked by factor. Now, the
production rule expression
in our grammar specification, traditionally called the start
symbol, can recognize inputs such as:
12345 -12345 +12345 1 + 2 1 * 2 1/2 + 3/4 1 + 2 + 3 + 4 1 * 2 * 3 * 4 (1 + 2) * (3 + 4) (-1 + 2) * (3 + -4) 1 + ((6 * 200) - 20) / 6 (1 + (2 + (3 + (4 + 5))))
Certainly we have modified the original EBNF syntax. This is done to conform to C++ syntax rules. Most notably we see the abundance of shift >> operators. Since there are no 'empty' operators in C++, it is simply not possible to write something like:
a b
as seen in math syntax, for example, to mean multiplication or, in our case,
as seen in EBNF syntax to mean sequencing (b should follow a). Spirit.Qi
uses the shift >> operator
instead for this purpose. We take the >>
operator, with arrows pointing to the right, to mean "is followed by".
Thus we write:
a >> b
The alternative operator | and
the parentheses () remain as is.
The assignment operator = is used
in place of EBNF's ::=. Last but
not least, the Kleene star *,
which in this case is a postfix operator in EBNF becomes a prefix. Instead
of:
a* //... in EBNF syntax,
we write:
*a //... in Spirit.
since there are no postfix stars, *,
in C/C++. Finally, we terminate each rule with the ubiquitous semi-colon,
;.
Spirit not only allows you to describe the structure of the input, it also enables the specification of the output format for your data in a similar way, and based on a single syntax and compatible semantics.
Let's assume we need to generate a textual representation from a simple data
structure such as a std::vector<int>. Conventional
code probably would look like:
std::vector<int> v (initialize_and_fill()); std::vector<int>::iterator end = v.end(); for (std::vector<int>::iterator it = v.begin(); it != end; ++it) std::cout << *it << std::endl;
which is not very flexible and quite difficult to maintain when it comes to changing the required output format. Spirit's sublibrary Karma allows you to specify output formats for arbitrary data structures in a very flexible way. The following snippet is the Karma format description used to create the same output as the traditional code above:
*(int_ << eol)
Here are some more examples of format descriptions for different output representations
of the same std::vector<int>:
Table 2. Different output formats for `std::vector<int>`
|
Format |
Example |
Description |
|---|---|---|
|
|
|
Comma separated list of integers |
|
|
|
Comma separated list of integers in parenthesis |
|
|
|
A list of hexadecimal numbers |
|
|
|
A list of floating point numbers |
We will see later in this documentation how it is possible to avoid printing
the trailing ','.
Overall, the syntax is similar to Spirit.Qi with the exception
that we use the << operator
for output concatenation. This should be easy to understand as it follows the
conventions used in the Standard's I/O streams.
Another important feature of Spirit.Karma allows you to fully decouple the data type from the output format. You can use the same output format with different data types as long as these conform conceptually. The next table gives some related examples.
Table 3. Different data types usable with the output format `*(int_ << eol)`
|
Data type |
Description |
|---|---|
|
|
C style arrays |
|
|
Standard vector |
|
|
Standard list |
|
|
Boost array |