Boost
C++ Libraries
Boost
C++ Libraries
...one of the most highly
regarded and expertly designed C++ library projects in the
world.
— Herb Sutter and Andrei
Alexandrescu, C++
Coding Standards
Boost
C++ Libraries
...one of the most highly
regarded and expertly designed C++ library projects in the
world.
— Herb Sutter and Andrei
Alexandrescu, C++
Coding Standards


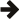
As already discussed, lexical scanning is the process of analyzing the
stream of input characters and separating it into strings called tokens,
most of the time separated by whitespace. The different token types recognized
by a lexical analyzer often get assigned unique integer token identifiers
(token ids). These token ids are normally used by the parser to identifiy
the current token without having to look at the matched string again.
The Spirit.Lex library is not different with respect
to this, as it uses the token ids as the main means of identification
of the different token types defined for a particular lexical analyzer.
However, it is different from commonly used lexical analyzers in the
sense that it returns (references to) instances of a (user defined) token
class to the user. The only limitation of this token class is that it
must carry at least the token id of the token it represents. For more
information about the interface a user defined token type has to expose
please look at the Token Class reference. The library provides a default
token type based on the Lexertl
library which should be sufficient in most cases: the lex::lexertl::token<> type. This section focusses on
the description of general features a token class may implement and how
this integrates with the other parts of the Spirit.Lex
library.
It is very important to understand the difference between a token definition
(represented by the lex::token_def<> template) and a token itself
(for instance represented by the lex::lexertl::token<> template).
The token definition is used to describe the main features of a particular token type, especially:
The token itself is a data structure returned by the lexer iterators. Dereferencing a lexer iterator returns a reference to the last matched token instance. It encapsulates the part of the underlying input sequence matched by the regular expression used during the definiton of this token type. Incrementing the lexer iterator invokes the lexical analyzer to match the next token by advancing the underlying input stream. The token data structure contains at least the token id of the matched token type, allowing to identify the matched character sequence. Optionally, the token instance may contain a token value and/or the lexer state this token instance was matched in. The following figure shows the schematic structure of a token.
The token value and the lexer state the token has been recognized in
may be omitted for optimization reasons, thus avoiding the need for the
token to carry more data than actually required. This configuration can
be achieved by supplying appropriate template parameters for the lex::lexertl::token<>
template while defining the token type.
The lexer iterator returns the same token type for each of the different
matched token definitions. To accomodate for the possible different token
value types exposed by the various token types (token
definitions), the general type of the token value is a Boost.Variant.
At a minimum (for the default configuration) this token value variant
will be configured to always hold a boost::iterator_range containing the
pair of iterators pointing to the matched input sequence for this token
instance.
![[Note]](../../../../images/note.png) |
Note |
|---|---|
If the lexical analyzer is used in conjunction with a Spirit.Qi
parser, the stored |
Here is the template prototype of the lex::lexertl::token<> template:
template < typename Iterator = char const*, typename AttributeTypes = mpl::vector0<>, typename HasState = mpl::true_ > struct lexertl_token;
where:
This is the type of the iterator used to access the underlying
input stream. It defaults to a plain char
const*.
This is either a mpl sequence containing all attribute types used
for the token definitions or the type omit.
If the mpl sequence is empty (which is the default), all token
instances will store a boost::iterator_range<Iterator> pointing to the start and the
end of the matched section in the input stream. If the type is
omit, the generated
tokens will contain no token value (attribute) at all.
This is either mpl::true_
or mpl::false_, allowing control as to
whether the generated token instances will contain the lexer state
they were generated in. The default is mpl::true_, so all token
instances will contain the lexer state.
Normally, during construction, a token instance always holds the boost::iterator_range as its token
value, unless it has been defined using the omit
token value type. This iterator range then is converted in place to the
requested token value type (attribute) when it is requested for the first
time.
The token definitions (represented by the lex::token_def<> template) are normally used as
part of the definition of the lexical analyzer. At the same time a token
definition instance may be used as a parser component in Spirit.Qi.
The template prototype of this class is shown here:
template< typename Attribute = unused_type, typename Char = char > class token_def;
where:
This is the type of the token value (attribute) supported by token
instances representing this token type. This attribute type is
exposed to the Spirit.Qi library, whenever
this token definition is used as a parser component. The default
attribute type is unused_type,
which means the token instance holds a boost::iterator_range pointing
to the start and the end of the matched section in the input stream.
If the attribute is omit
the token instance will expose no token type at all. Any other
type will be used directly as the token value type.
This is the value type of the iterator for the underlying input
sequence. It defaults to char.
The semantics of the template parameters for the token type and the token
definition type are very similar and interdependent. As a rule of thumb
you can think of the token definition type as the means of specifying
everything related to a single specific token type (such as identifier or integer).
On the other hand the token type is used to define the general properties
of all token instances generated by the Spirit.Lex
library.
![[Important]](../../../../images/important.png) |
Important |
|---|---|
|
If you don't list any token value types in the token type definition
declaration (resulting in the usage of the default
But as soon as you specify at least one token value type while defining
the token type you'll have to list all value types used for |
lex::lexertl::token<>
Let's start with some examples. We refer to one of the Spirit.Lex examples (for the full source code of this example please see example4.cpp).
The first code snippet shows an excerpt of the token definition class,
the definition of a couple of token types. Some of the token types do
not expose a special token value (if_,
else_, and while_). Their token value will always
hold the iterator range of the matched input sequence. The token definitions
for the identifier and
the integer constant
are specialized to expose an explicit token type each: std::string and unsigned
int.
// these tokens expose the iterator_range of the matched input sequence lex::token_def<> if_, else_, while_; // The following two tokens have an associated attribute type, 'identifier' // carries a string (the identifier name) and 'constant' carries the // matched integer value. // // Note: any token attribute type explicitly specified in a token_def<> // declaration needs to be listed during token type definition as // well (see the typedef for the token_type below). // // The conversion of the matched input to an instance of this type occurs // once (on first access), which makes token attributes as efficient as // possible. Moreover, token instances are constructed once by the lexer // library. From this point on tokens are passed by reference only, // avoiding them being copied around. lex::token_def<std::string> identifier; lex::token_def<unsigned int> constant;
As the parsers generated by Spirit.Qi are fully
attributed, any Spirit.Qi parser component needs
to expose a certain type as its parser attribute. Naturally, the lex::token_def<>
exposes the token value type as its parser attribute, enabling a smooth
integration with Spirit.Qi.
The next code snippet demonstrates how the required token value types are specified while defining the token type to use. All of the token value types used for at least one of the token definitions have to be re-iterated for the token definition as well.
// This is the lexer token type to use. The second template parameter lists // all attribute types used for token_def's during token definition (see // calculator_tokens<> above). Here we use the predefined lexertl token // type, but any compatible token type may be used instead. // // If you don't list any token attribute types in the following declaration // (or just use the default token type: lexertl_token<base_iterator_type>) // it will compile and work just fine, just a bit less efficient. This is // because the token attribute will be generated from the matched input // sequence every time it is requested. But as soon as you specify at // least one token attribute type you'll have to list all attribute types // used for token_def<> declarations in the token definition class above, // otherwise compilation errors will occur. typedef lex::lexertl::token< base_iterator_type, boost::mpl::vector<unsigned int, std::string> > token_type;
To avoid the token to have a token value at all, the special tag omit can be used: token_def<omit> and lexertl_token<base_iterator_type, omit>.