 Boost
C++ Libraries
Boost
C++ Libraries
...one of the most highly
regarded and expertly designed C++ library projects in the
world.
— Herb Sutter and Andrei
Alexandrescu, C++
Coding Standards
Boost
C++ Libraries
...one of the most highly
regarded and expertly designed C++ library projects in the
world.
— Herb Sutter and Andrei
Alexandrescu, C++
Coding Standards


Imagine that we have two samples, and we wish to determine whether their means are different or not. This situation often arises when determining whether a new process or treatment is better than an old one.
In this example, we'll be using the Car Mileage sample data from the NIST website. The data compares miles per gallon of US cars with miles per gallon of Japanese cars.
The sample code is in students_t_two_samples.cpp.
There are two ways in which this test can be conducted: we can assume that the true standard deviations of the two samples are equal or not. If the standard deviations are assumed to be equal, then the calculation of the t-statistic is greatly simplified, so we'll examine that case first. In real life we should verify whether this assumption is valid with a Chi-Squared test for equal variances.
We begin by defining a procedure that will conduct our test assuming equal variances:
// Needed headers: #include <boost/math/distributions/students_t.hpp> #include <iostream> #include <iomanip> // Simplify usage: using namespace boost::math; using namespace std; void two_samples_t_test_equal_sd( double Sm1, // Sm1 = Sample 1 Mean. double Sd1, // Sd1 = Sample 1 Standard Deviation. unsigned Sn1, // Sn1 = Sample 1 Size. double Sm2, // Sm2 = Sample 2 Mean. double Sd2, // Sd2 = Sample 2 Standard Deviation. unsigned Sn2, // Sn2 = Sample 2 Size. double alpha) // alpha = Significance Level. {
Our procedure will begin by calculating the t-statistic, assuming equal variances the needed formulae are:
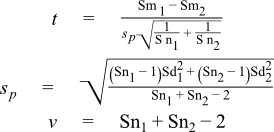
where Sp is the "pooled" standard deviation of the two samples, and v is the number of degrees of freedom of the two combined samples. We can now write the code to calculate the t-statistic:
// Degrees of freedom: double v = Sn1 + Sn2 - 2; cout << setw(55) << left << "Degrees of Freedom" << "= " << v << "\n"; // Pooled variance: double sp = sqrt(((Sn1-1) * Sd1 * Sd1 + (Sn2-1) * Sd2 * Sd2) / v); cout << setw(55) << left << "Pooled Standard Deviation" << "= " << sp << "\n"; // t-statistic: double t_stat = (Sm1 - Sm2) / (sp * sqrt(1.0 / Sn1 + 1.0 / Sn2)); cout << setw(55) << left << "T Statistic" << "= " << t_stat << "\n";
The next step is to define our distribution object, and calculate the complement of the probability:
students_t dist(v); double q = cdf(complement(dist, fabs(t_stat))); cout << setw(55) << left << "Probability that difference is due to chance" << "= " << setprecision(3) << scientific << 2 * q << "\n\n";
Here we've used the absolute value of the t-statistic, because we initially want to know simply whether there is a difference or not (a two-sided test). However, we can also test whether the mean of the second sample is greater or is less (one-sided test) than that of the first: all the possible tests are summed up in the following table:
|
Hypothesis |
Test |
|---|---|
|
The Null-hypothesis: there is no difference in means |
Reject if complement of CDF for |t| < significance level / 2:
|
|
The Alternative-hypothesis: there is a difference in means |
Reject if complement of CDF for |t| > significance level / 2:
|
|
The Alternative-hypothesis: Sample 1 Mean is less than Sample 2 Mean. |
Reject if CDF of t > significance level:
|
|
The Alternative-hypothesis: Sample 1 Mean is greater than Sample 2 Mean. |
Reject if complement of CDF of t > significance level:
|
![[Note]](../../../../../../../../../../doc/src/images/note.png) |
Note |
|---|---|
For a two-sided test we must compare against alpha / 2 and not alpha. |
Most of the rest of the sample program is pretty-printing, so we'll skip over that, and take a look at the sample output for alpha=0.05 (a 95% probability level). For comparison the dataplot output for the same data is in section 1.3.5.3 of the NIST/SEMATECH e-Handbook of Statistical Methods..
________________________________________________ Student t test for two samples (equal variances) ________________________________________________ Number of Observations (Sample 1) = 249 Sample 1 Mean = 20.145 Sample 1 Standard Deviation = 6.4147 Number of Observations (Sample 2) = 79 Sample 2 Mean = 30.481 Sample 2 Standard Deviation = 6.1077 Degrees of Freedom = 326 Pooled Standard Deviation = 6.3426 T Statistic = -12.621 Probability that difference is due to chance = 5.273e-030 Results for Alternative Hypothesis and alpha = 0.0500 Alternative Hypothesis Conclusion Sample 1 Mean != Sample 2 Mean NOT REJECTED Sample 1 Mean < Sample 2 Mean NOT REJECTED Sample 1 Mean > Sample 2 Mean REJECTED
So with a probability that the difference is due to chance of just 5.273e-030, we can safely conclude that there is indeed a difference.
The tests on the alternative hypothesis show that we must also reject the hypothesis that Sample 1 Mean is greater than that for Sample 2: in this case Sample 1 represents the miles per gallon for Japanese cars, and Sample 2 the miles per gallon for US cars, so we conclude that Japanese cars are on average more fuel efficient.
Now that we have the simple case out of the way, let's look for a moment at the more complex one: that the standard deviations of the two samples are not equal. In this case the formula for the t-statistic becomes:
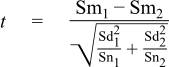
And for the combined degrees of freedom we use the Welch-Satterthwaite approximation:

Note that this is one of the rare situations where the degrees-of-freedom parameter to the Student's t distribution is a real number, and not an integer value.
|
Note |
|---|---|
Some statistical packages truncate the effective degrees of freedom to an integer value: this may be necessary if you are relying on lookup tables, but since our code fully supports non-integer degrees of freedom there is no need to truncate in this case. Also note that when the degrees of freedom is small then the Welch-Satterthwaite approximation may be a significant source of error. |
Putting these formulae into code we get:
// Degrees of freedom: double v = Sd1 * Sd1 / Sn1 + Sd2 * Sd2 / Sn2; v *= v; double t1 = Sd1 * Sd1 / Sn1; t1 *= t1; t1 /= (Sn1 - 1); double t2 = Sd2 * Sd2 / Sn2; t2 *= t2; t2 /= (Sn2 - 1); v /= (t1 + t2); cout << setw(55) << left << "Degrees of Freedom" << "= " << v << "\n"; // t-statistic: double t_stat = (Sm1 - Sm2) / sqrt(Sd1 * Sd1 / Sn1 + Sd2 * Sd2 / Sn2); cout << setw(55) << left << "T Statistic" << "= " << t_stat << "\n";
Thereafter the code and the tests are performed the same as before. Using are car mileage data again, here's what the output looks like:
__________________________________________________ Student t test for two samples (unequal variances) __________________________________________________ Number of Observations (Sample 1) = 249 Sample 1 Mean = 20.145 Sample 1 Standard Deviation = 6.4147 Number of Observations (Sample 2) = 79 Sample 2 Mean = 30.481 Sample 2 Standard Deviation = 6.1077 Degrees of Freedom = 136.87 T Statistic = -12.946 Probability that difference is due to chance = 1.571e-025 Results for Alternative Hypothesis and alpha = 0.0500 Alternative Hypothesis Conclusion Sample 1 Mean != Sample 2 Mean NOT REJECTED Sample 1 Mean < Sample 2 Mean NOT REJECTED Sample 1 Mean > Sample 2 Mean REJECTED
This time allowing the variances in the two samples to differ has yielded a higher likelihood that the observed difference is down to chance alone (1.571e-025 compared to 5.273e-030 when equal variances were assumed). However, the conclusion remains the same: US cars are less fuel efficient than Japanese models.