 Boost
C++ Libraries
Boost
C++ Libraries
...one of the most highly
regarded and expertly designed C++ library projects in the
world.
— Herb Sutter and Andrei
Alexandrescu, C++
Coding Standards
Boost
C++ Libraries
...one of the most highly
regarded and expertly designed C++ library projects in the
world.
— Herb Sutter and Andrei
Alexandrescu, C++
Coding Standards


#include <boost/math/distributions/binomial.hpp>
namespace boost{ namespace math{ template <class RealType = double, class Policy = policies::policy<> > class binomial_distribution; typedef binomial_distribution<> binomial; template <class RealType, class Policy> class binomial_distribution { public: typedef RealType value_type; typedef Policy policy_type; static const unspecified-type clopper_pearson_exact_interval; static const unspecified-type jeffreys_prior_interval; // construct: binomial_distribution(RealType n, RealType p); // parameter access:: RealType success_fraction() const; RealType trials() const; // Bounds on success fraction: static RealType find_lower_bound_on_p( RealType trials, RealType successes, RealType probability, unspecified-type method = clopper_pearson_exact_interval); static RealType find_upper_bound_on_p( RealType trials, RealType successes, RealType probability, unspecified-type method = clopper_pearson_exact_interval); // estimate min/max number of trials: static RealType find_minimum_number_of_trials( RealType k, // number of events RealType p, // success fraction RealType alpha); // risk level static RealType find_maximum_number_of_trials( RealType k, // number of events RealType p, // success fraction RealType alpha); // risk level }; }} // namespaces
The class type binomial_distribution
represents a binomial
distribution: it is used when there are exactly two mutually exclusive
outcomes of a trial. These outcomes are labelled "success" and
"failure". The Binomial
Distribution is used to obtain the probability of observing k successes
in N trials, with the probability of success on a single trial denoted
by p. The binomial distribution assumes that p is fixed for all trials.
![[Note]](../../../../../../../doc/src/images/note.png) |
Note |
|---|---|
The random variable for the binomial distribution is the number of successes, (the number of trials is a fixed property of the distribution) whereas for the negative binomial, the random variable is the number of trials, for a fixed number of successes. |
The PDF for the binomial distribution is given by:

The following two graphs illustrate how the PDF changes depending upon the distributions parameters, first we'll keep the success fraction p fixed at 0.5, and vary the sample size:
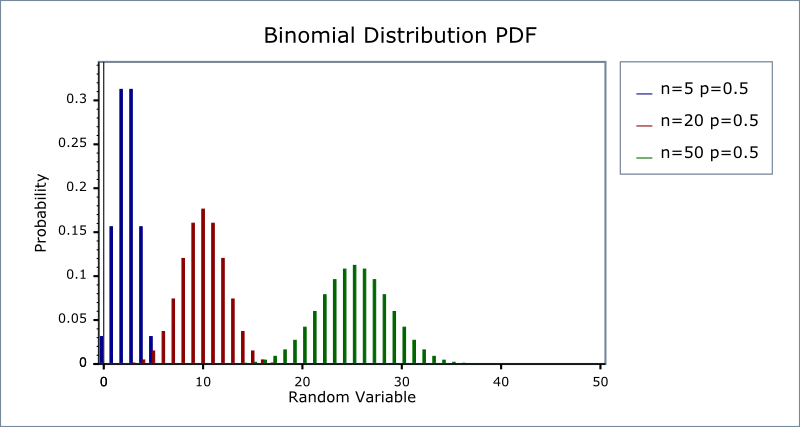
Alternatively, we can keep the sample size fixed at N=20 and vary the success fraction p:

![[Caution]](../../../../../../../doc/src/images/caution.png) |
Caution |
|---|---|
|
The Binomial distribution is a discrete distribution: internally, functions
like the The quantile function will by default return an integer result that has been rounded outwards. That is to say lower quantiles (where the probability is less than 0.5) are rounded downward, and upper quantiles (where the probability is greater than 0.5) are rounded upwards. This behaviour ensures that if an X% quantile is requested, then at least the requested coverage will be present in the central region, and no more than the requested coverage will be present in the tails. This behaviour can be changed so that the quantile functions are rounded differently, or even return a real-valued result using Policies. It is strongly recommended that you read the tutorial Understanding Quantiles of Discrete Distributions before using the quantile function on the Binomial distribution. The reference docs describe how to change the rounding policy for these distributions. |
binomial_distribution(RealType n, RealType p);
Constructor: n is the total number of trials, p is the probability of success of a single trial.
Requires 0 <=
p <=
1, and n
>= 0,
otherwise calls domain_error.
RealType success_fraction() const;
Returns the parameter p from which this distribution was constructed.
RealType trials() const;
Returns the parameter n from which this distribution was constructed.
static RealType find_lower_bound_on_p( RealType trials, RealType successes, RealType alpha, unspecified-type method = clopper_pearson_exact_interval);
Returns a lower bound on the success fraction:
The total number of trials conducted.
The number of successes that occurred.
The largest acceptable probability that the true value of the success fraction is less than the value returned.
An optional parameter that specifies the method to be used to compute the interval (See below).
For example, if you observe k successes from n trials the best estimate for the success fraction is simply k/n, but if you want to be 95% sure that the true value is greater than some value, pmin, then:
pmin = binomial_distribution<RealType>::find_lower_bound_on_p( n, k, 0.05);
There are currently two possible values available for the method
optional parameter: clopper_pearson_exact_interval
or jeffreys_prior_interval. These constants are both
members of class template binomial_distribution,
so usage is for example:
p = binomial_distribution<RealType>::find_lower_bound_on_p( n, k, 0.05, binomial_distribution<RealType>::jeffreys_prior_interval);
The default method if this parameter is not specified is the Clopper Pearson
"exact" interval. This produces an interval that guarantees at
least 100(1-alpha)% coverage, but which is known to be overly
conservative, sometimes producing intervals with much greater than the
requested coverage.
The alternative calculation method produces a non-informative Jeffreys
Prior interval. It produces 100(1-alpha)%
coverage only in the average case, though is typically
very close to the requested coverage level. It is one of the main methods
of calculation recommended in the review by Brown, Cai and DasGupta.
Please note that the "textbook" calculation method using a normal approximation (the Wald interval) is deliberately not provided: it is known to produce consistently poor results, even when the sample size is surprisingly large. Refer to Brown, Cai and DasGupta for a full explanation. Many other methods of calculation are available, and may be more appropriate for specific situations. Unfortunately there appears to be no consensus amongst statisticians as to which is "best": refer to the discussion at the end of Brown, Cai and DasGupta for examples.
The two methods provided here were chosen principally because they can be used for both one and two sided intervals. See also:
Lawrence D. Brown, T. Tony Cai and Anirban DasGupta (2001), Interval Estimation for a Binomial Proportion, Statistical Science, Vol. 16, No. 2, 101-133.
T. Tony Cai (2005), One-sided confidence intervals in discrete distributions, Journal of Statistical Planning and Inference 131, 63-88.
Agresti, A. and Coull, B. A. (1998). Approximate is better than "exact" for interval estimation of binomial proportions. Amer. Statist. 52 119-126.
Clopper, C. J. and Pearson, E. S. (1934). The use of confidence or fiducial limits illustrated in the case of the binomial. Biometrika 26 404-413.
static RealType find_upper_bound_on_p( RealType trials, RealType successes, RealType alpha, unspecified-type method = clopper_pearson_exact_interval);
Returns an upper bound on the success fraction:
The total number of trials conducted.
The number of successes that occurred.
The largest acceptable probability that the true value of the success fraction is greater than the value returned.
An optional parameter that specifies the method to be used to compute
the interval. Refer to the documentation for find_upper_bound_on_p
above for the meaning of the method options.
For example, if you observe k successes from n trials the best estimate for the success fraction is simply k/n, but if you want to be 95% sure that the true value is less than some value, pmax, then:
pmax = binomial_distribution<RealType>::find_upper_bound_on_p( n, k, 0.05);
|
Note |
|---|---|
|
In order to obtain a two sided bound on the success fraction, you call
both If the desired risk level that the true success fraction lies outside the bounds is α, then you pass α/2 to these functions. So for example a two sided 95% confidence interval would be obtained by passing α = 0.025 to each of the functions. |
static RealType find_minimum_number_of_trials( RealType k, // number of events RealType p, // success fraction RealType alpha); // probability threshold
This function estimates the minimum number of trials required to ensure that more than k events is observed with a level of risk alpha that k or fewer events occur.
The number of success observed.
The probability of success for each trial.
The maximum acceptable probability that k events or fewer will be observed.
For example:
binomial_distribution<RealType>::find_number_of_trials(10, 0.5, 0.05);
Returns the smallest number of trials we must conduct to be 95% sure of seeing 10 events that occur with frequency one half.
static RealType find_maximum_number_of_trials( RealType k, // number of events RealType p, // success fraction RealType alpha); // probability threshold
This function estimates the maximum number of trials we can conduct to ensure that k successes or fewer are observed, with a risk alpha that more than k occur.
The number of success observed.
The probability of success for each trial.
The maximum acceptable probability that more than k events will be observed.
For example:
binomial_distribution<RealType>::find_maximum_number_of_trials(0, 1e-6, 0.05);
Returns the largest number of trials we can conduct and still be 95% certain of not observing any events that occur with one in a million frequency. This is typically used in failure analysis.
All the usual non-member accessor functions that are generic to all distributions are supported: Cumulative Distribution Function, Probability Density Function, Quantile, Hazard Function, Cumulative Hazard Function, mean, median, mode, variance, standard deviation, skewness, kurtosis, kurtosis_excess, range and support.
The domain for the random variable k is 0 <= k <= N, otherwise a domain_error
is returned.
It's worth taking a moment to define what these accessors actually mean in the context of this distribution:
Table 2.1. Meaning of the non-member accessors
|
Function |
Meaning |
|---|---|
|
The probability of obtaining exactly k successes from n trials with success fraction p. For example:
|
|
|
The probability of obtaining k successes or fewer from n trials with success fraction p. For example:
|
|
|
The probability of obtaining more than k successes from n trials with success fraction p. For example:
|
|
|
The greatest number of successes that may be observed from n trials with success fraction p, at probability P. Note that the value returned is a real-number, and not an integer. Depending on the use case you may want to take either the floor or ceiling of the result. For example:
|
|
|
The smallest number of successes that may be observed from n trials with success fraction p, at probability P. Note that the value returned is a real-number, and not an integer. Depending on the use case you may want to take either the floor or ceiling of the result. For example:
|
Various worked examples are available illustrating the use of the binomial distribution.
This distribution is implemented using the incomplete beta functions ibeta and ibetac, please refer to these functions for information on accuracy.
In the following table p is the probability that one trial will be successful (the success fraction), n is the number of trials, k is the number of successes, p is the probability and q = 1-p.
|
Function |
Implementation Notes |
|---|---|
|
|
Implementation is in terms of ibeta_derivative: if nCk is the binomial coefficient of a and b, then we have:
Which can be evaluated as The function ibeta_derivative is used here, since it has already been optimised for the lowest possible error - indeed this is really just a thin wrapper around part of the internals of the incomplete beta function. There are also various special cases: refer to the code for details. |
|
cdf |
Using the relation: p = I[sub 1-p](n - k, k + 1) = 1 - I[sub p](k + 1, n - k) = ibetac(k + 1, n - k, p) There are also various special cases: refer to the code for details. |
|
cdf complement |
Using the relation: q = ibeta(k + 1, n - k, p) There are also various special cases: refer to the code for details. |
|
quantile |
Since the cdf is non-linear in variate k none of the inverse incomplete beta functions can be used here. Instead the quantile is found numerically using a derivative free method (TOMS Algorithm 748). |
|
quantile from the complement |
Found numerically as above. |
|
mean |
|
|
variance |
|
|
mode |
|
|
skewness |
|
|
kurtosis |
|
|
kurtosis excess |
|
|
parameter estimation |
The member functions |
