 Boost
C++ Libraries
Boost
C++ Libraries
...one of the most highly
regarded and expertly designed C++ library projects in the
world.
— Herb Sutter and Andrei
Alexandrescu, C++
Coding Standards
Boost
C++ Libraries
...one of the most highly
regarded and expertly designed C++ library projects in the
world.
— Herb Sutter and Andrei
Alexandrescu, C++
Coding Standards
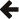



#include <boost/math/quadrature/naive_monte_carlo.hpp> namespace boost { namespace math { namespace quadrature { template<class Real, class F, class RNG = std::mt19937_64, class Policy = boost::math::policies::policy<>> class naive_monte_carlo { public: naive_monte_carlo(const F& integrand, std::vector<std::pair<Real, Real>> const & bounds, Real error_goal, bool singular = true, size_t threads = std::thread::hardware_concurrency()); std::future<Real> integrate(); void cancel(); Real current_error_estimate() const; std::chrono::duration<Real> estimated_time_to_completion() const; void update_target_error(Real new_target_error); Real progress() const; Real current_estimate() const; size_t calls() const; }; }}} // namespaces
The class naive_monte_carlo
performs Monte-Carlo integration on a square integrable function f
on a domain Ω. The theoretical background of Monte-Carlo integration is nicely
discussed at Wikipedia,
and as such will not be discussed here. However, despite being "naive",
it is a mistake to assume that naive Monte-Carlo integration is not powerful,
as the simplicity of the method affords a robustness not easily provided by
more sophisticated tools. The multithreaded nature of the routine allows us
to compute a large number of sample points with great speed, and hence the
slow convergence is mitigated by exploiting the full power of modern hardware.
The naive Monte-Carlo integration provided by Boost exemplifies the programming techniques needed to cope with high-performance computing. For instance, since the convergence is only 𝑶(N-1/2), the compute time is very sensitive to the error goal. Users can easily specify an error goal which causes computation to last months-or just a few seconds. Without progress reporting, this situation is disorienting and causes the user to behave in a paranoid manner. Even with progress reporting, a user might need to cancel a job due to shifting priorities of the employing institution, and as such cancellation must be supported. A cancelled job which returns no results is wasted, so the cancellation must be graceful, returning the best estimate of the result thus far. In addition, a task might finish, and the user may well decide to try for a lower error bound. Hence restarting without loss of the preceding effort must be supported. Finally, on an HPC system, we generally wish to use all available threads. But if the computation is performed on a users workstation, employing every thread will cause the browser, email, or music apps to become unresponsive, so leaving a single thread available for other apps is appreciated.
All these use cases are supported, so let's get to the code:
// Define a function to integrate: auto g = [](std::vector<double> const & x) { constexpr const double A = 1.0 / (M_PI * M_PI * M_PI); return A / (1.0 - cos(x[0])*cos(x[1])*cos(x[2])); }; std::vector<std::pair<double, double>> bounds{{0, M_PI}, {0, M_PI}, {0, M_PI}}; double error_goal = 0.001 naive_monte_carlo<double, decltype(g)> mc(g, bounds, error_goal); std::future<double> task = mc.integrate(); while (task.wait_for(std::chrono::seconds(1)) != std::future_status::ready) { // The user must decide on a reasonable way to display the progress depending on their environment: display_progress(mc.progress(), mc.current_error_estimate(), mc.current_estimate(), mc.estimated_time_to_completion()); if (some_signal_heard()) { mc.cancel(); std::cout << "\nCancelling because this is too slow!\n"; } } double y = task.get();
First off, we define the function we wish to integrate. This function must
accept a std::vector<Real> const &,
and return a Real. Next, we
define the domain of integration. Infinite domains are indicated by the bound
std::numeric_limits<Real>::infinity().
The call
naive_monte_carlo<double, decltype(g)> mc(g, bounds, error_goal);
creates an instance of the monte carlo integrator. This is also where the number of threads can be set, for instance
naive_monte_carlo<double, decltype(g)> mc(g, bounds, error_goal, true, std::thread::hardware_concurrency() - 1);
might be more appropriate for running on a user's hardware (the default taking
all the threads). The call to integrate() does not return the value of the integral,
but rather a std::future<Real>.
This allows us to do progress reporting from the master thread via
while (task.wait_for(std::chrono::seconds(1)) != std::future_status::ready) { // some reasonable method of displaying progress, based on the requirements of your app. display_progress(mc.progress(), mc.current_error_estimate(), mc.current_estimate(), mc.estimated_time_to_completion()); }
The file example/naive_monte_carlo_example.cpp has an implementation of display_progress which is reasonable for
command line apps. In addition, we can call mc.cancel()
in this loop to stop the integration. Progress reporting is especially useful
if you accidentally pass in an integrand which is not square integrable-the
variance increases without bound, and the progress decreases from some noisy
initial value down to zero with time. Calling task.get()
returns the current estimate. Once the future is ready, we can get the value
of the integral via
double result = task.get();
At this point, the user may wish to reduce the error goal. This is achieved by
double new_target_error = 0.0005; mc.update_target_error(new_target_error); task = mc.integrate(); y = task.get();
There is one additional "advanced" parameter: Whether or not the integrand is singular on the boundary. If the integrand is not singular on the boundary, then the integrand is evaluated over the closed set ∏i [ ai, bi ]. If the integrand is singular (the default) then the integrand is evaluated over the closed set ∏i [ /a(1+ε)/, /b(1-ε)/ ]. (Note that there is sadly no such thing as an open set in floating point arithmetic.) When does the difference matter? Recall the stricture to never peel a high-dimensional orange, because when you do, nothing is left. The same idea applied here. The fraction of the volume within a distance ε of the boundary is approximately εd, where d is the number of dimensions. If the number of dimensions is large and the precision of the type is low, then it is possible that no correct digits will be obtained. If the integrand is singular on the boundary, you have no options; you simply must resort to higher precision computations. If the integrand is not singular on the boundary, then you can tell this to the integration routine via
naive_monte_carlo<double, decltype(g)> mc(g, bounds, error_goal, /*singular = */ false);
and this problem will not be encountered. In practice, you will need ~1,000 dimensions for this to be relevant in 16 bit floating point, ~100,000 dimensions in 32 bit floating point, and an astronomical number of dimensions in double precision.
Finally, alternative random number generators may be provided to the class.
The default random number generator is the standard library std::mt19937_64.
However, here is an example which uses the 32-bit Mersenne twister random number
generator instead:
naive_monte_carlo<Real, decltype(g), std::mt19937> mc(g, bounds, (Real) 0.001);