 Boost
C++ Libraries
Boost
C++ Libraries
...one of the most highly
regarded and expertly designed C++ library projects in the
world.
— Herb Sutter and Andrei
Alexandrescu, C++
Coding Standards
Boost
C++ Libraries
...one of the most highly
regarded and expertly designed C++ library projects in the
world.
— Herb Sutter and Andrei
Alexandrescu, C++
Coding Standards



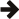
#include <boost/math/differentiation/lanczos_smoothing.hpp> namespace boost::math::differentiation { template <class Real, size_t order=1> class discrete_lanczos_derivative { public: discrete_lanczos_derivative(Real spacing, size_t n = 18, size_t approximation_order = 3); template<class RandomAccessContainer> Real operator()(RandomAccessContainer const & v, size_t i) const; template<class RandomAccessContainer> void operator()(RandomAccessContainer const & v, RandomAccessContainer & dvdt) const; template<class RandomAccessContainer> RandomAccessContainer operator()(RandomAccessContainer const & v) const; Real get_spacing() const; }; } // namespaces
The discrete_lanczos_derivative
class calculates a finite-difference approximation to the derivative of a noisy
sequence of equally-spaced values v. A basic usage is
std::vector<double> v(500); // fill v with noisy data. double spacing = 0.001; using boost::math::differentiation::discrete_lanczos_derivative; auto lanczos = discrete_lanczos_derivative(spacing); // Compute dvdt at index 30: double dvdt30 = lanczos(v, 30); // Compute derivative of entire vector: std::vector<double> dvdt = lanczos(v);
Noise-suppressing second derivatives can also be computed. The syntax is as follows:
std::vector<double> v(500); // fill v with noisy data. auto lanczos = lanczos_derivative<double, 2>(spacing); // evaluate second derivative at a point: double d2vdt2 = lanczos(v, 18); // evaluate second derivative of entire vector: std::vector<double> d2vdt2 = lanczos(v);
For memory conscious programmers, you can reuse the memory space for the derivative as follows:
std::vector<double> v(500); std::vector<double> dvdt(500); // . . . define spacing, create and instance of discrete_lanczos_derivative // populate dvdt, perhaps in a loop: lanczos(v, dvdt);
If the data has variance σ2, then the variance of the computed derivative is roughly σ2p3 n-3 Δ t-2, i.e., it increases cubically with the approximation order p, linearly with the data variance, and decreases at the cube of the filter length n. In addition, we must not forget the discretization error which is O(Δ tp). You can play around with the approximation order p and the filter length n:
size_t n = 12; size_t p = 2; auto lanczos = lanczos_derivative(spacing, n, p); double dvdt = lanczos(v, i);
If p=2n, then the discrete Lanczos derivative is not smoothing: It reduces to the standard 2n+1-point finite-difference formula. For p>2n, an assertion is hit as the filter is undefined.
In our tests with AWGN, we have found the error decreases monotonically with n, as is expected from the theory discussed above. So the choice of n is simple: As high as possible given your speed requirements (larger n implies a longer filter and hence more compute), balanced against the danger of overfitting and averaging over non-stationarity.
The choice of approximation order p for a given n is more difficult. If your signal is believed to be a polynomial, it does not make sense to set p to larger than the polynomial degree- though it may be sensible to take p less than this.
For a sinusoidal signal contaminated with AWGN, we ran a few tests showing that for SNR = 1, p = n/8 gave the best results, for SNR = 10, p = n/7 was the best, and for SNR = 100, p = n/6 was the most reasonable choice. For SNR = 0.1, the method appears to be useless. The user is urged to use these results with caution: they have no theoretical backing and are extrapolated from a single case.
The filters are (regrettably) computed at runtime-the vast number of combinations of approximation order and filter length makes the number of filters that must be stored excessive for compile-time data. The constructor call computes the filters. Since each filter has length 2n+1 and there are n filters, whose element each consist of p summands, the complexity of the constructor call is O(n2p). This is not cheap-though for most cases small p and n not too large (< 20) is desired. However, for concreteness, on the author's 2.7GHz Intel laptop CPU, the n=16, p=3 filter takes 9 microseconds to compute. This is far from negligible, and as such the filters may be used with multiple data, and even shared between threads:
std::vector<double> v1(500); std::vector<double> v2(500); // fill v1, v2 with noisy data. auto lanczos = lanczos_derivative(spacing); std::vector<double> dv1dt = lanczos(v1); // threadsafe std::vector<double> dv2dt = lanczos(v2); // threadsafe // need to use a different spacing? lanczos.reset_spacing(0.02); // not threadsafe
The implementation follows McDevitt, 2012, who vastly expanded the ideas of Lanczos to create a very general framework for numerically differentiating noisy equispaced data.
We have extracted some data from the LIGO signal and differentiated it using the (n, p) = (60, 4) Lanczos smoothing derivative, as well as using the (n, p) = (4, 8) (nonsmoothing) derivative.
The original data is in orange, the smoothing derivative in blue, and the non-smoothing standard finite difference formula is in gray. (Each time series has been rescaled to fit in the same graph.) We can see that the smoothing derivative tracks the increase and decrease in the trend well, whereas the standard finite difference formula produces nonsense and amplifies noise.
The computation of the filters is ill-conditioned for large p. In order to mitigate this problem, we have computed the filters in higher precision and cast the results to the desired type. However, this simply pushes the problem to larger p. In practice, this is not a problem, as large p corresponds to less powerful denoising, but keep it in mind.
In addition, the -ffast-math flag
has a very large effect on the speed of these functions. In our benchmarks,
they were 50% faster with the flag enabled, which is much larger than the usual
performance increases we see by turning on this flag. Hence, if the default
performance is not sufficient, this flag is available, though it comes with
its own problems.
This requires C++17 if constexpr.
