 Boost
C++ Libraries
Boost
C++ Libraries
...one of the most highly
regarded and expertly designed C++ library projects in the
world.
— Herb Sutter and Andrei
Alexandrescu, C++
Coding Standards
Boost
C++ Libraries
...one of the most highly
regarded and expertly designed C++ library projects in the
world.
— Herb Sutter and Andrei
Alexandrescu, C++
Coding Standards


Boost.Log was designed to be very modular and extensible. It supports both narrow-character and wide-character logging. Both narrow and wide-character loggers provide similar capabilities, so through most of the documentation only the narrow-character interface will be described.
The library consists of three main layers: the layer of log data collection, the layer of processing the collected data and the central hub that interconnects the former two layers. The design is presented on the figure below.
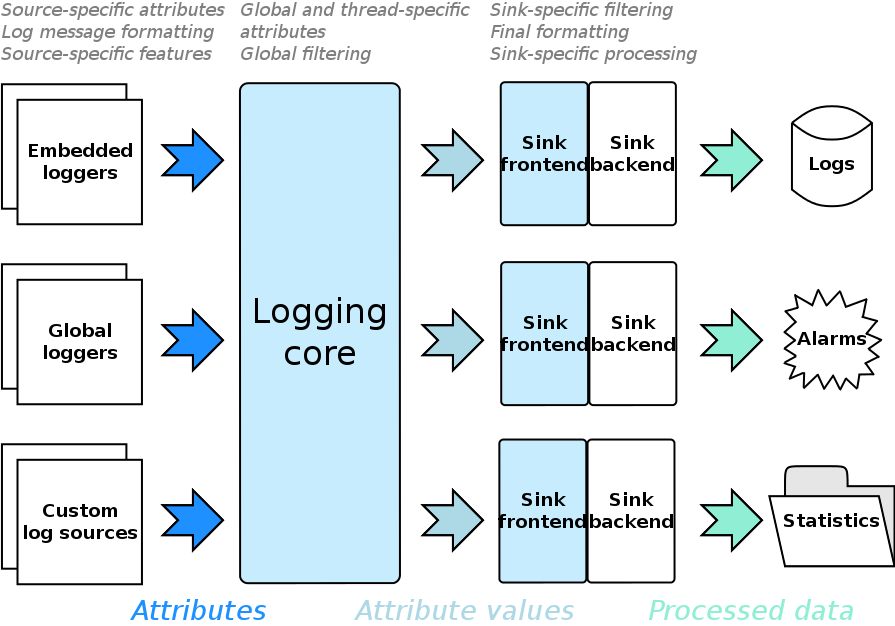
The arrows show the direction of logging information flow - from parts of your application, at the left, to the final storage, (if any) at the right. The storage is optional because the result of log processing may include some actions without actually storing the information anywhere. For example, if your application is in a critical state, it can emit a special log record that will be processed so that the user sees an error message as a tool-tip notification over the application icon in the system tray and hears an alarming sound. This is a very important library feature: it is orthogonal to collecting, processing logging data and, in fact, what data logging records consist of. This allows for use of the library not only for classic logging, but to indicate some important events to the application user and accumulate statistical data.
Getting back to the figure, in the left side your application emits log records with help of loggers - special objects that provide streams to format messages that will eventually be put to log. The library provides a number of different logger types and you can craft many more yourself, extending the existing ones. Loggers are designed as a mixture of distinct features that can be combined with each other in any combination. You can simply develop your own feature and add it to the soup. You will be able to use the constructed logger just like the others - embed it into your application classes or create and use a global instance of the logger. Either approach provides its benefits. Embedding a logger into some class provides a way to differentiate logs from different instances of the class. On the other hand, in functional-style programming it is usually more convenient to have a single global logger somewhere and have a simple access to it.
Generally speaking, the library does not require the use of loggers to write logs. The more generic term "log source" designates the entity that initiates logging by constructing a log record. Other log sources might include captured console output of a child application or data received from network. However, loggers are the most common kind of log sources.
In order to initiate logging a log source must pass all data, associated with the log record, to the logging core. This data or, more precisely, the logic of the data acquisition is represented with a set of named attributes. Each attribute is, basically, a function, whose result is called "attribute value" and is actually processed on further stages. An example of an attribute is a function that returns the current time. Its result - the particular time point - is the attribute value.
There are three kinds of attribute sets:
You can see in the figure that the former two sets are maintained by the logging core and thus need not be passed by the log source in order to initiate logging. Attributes that participate in the global attribute set are attached to any log record ever made. Obviously, thread-specific attributes are attached only to the records made from the thread in which they were registered in the set. The source-specific attribute set is maintained by the source that initiates logging, these attributes are attached only to the records being made through that particular source.
When a source initiates logging, attribute values are acquired from attributes of all three attribute sets. These attribute values then form a single set of named attribute values, which is processed further. You can add more attribute values to the set; these values will only be attached to the particular log record and will not be associated with the logging source or logging core. As you may notice, it is possible for a same-named attribute to appear in several attribute sets. Such conflicts are solved on priority basis: global attributes have the least priority, source-specific attributes have the highest; the lower priority attributes are discarded from consideration in case of conflicts.
When the set of attribute values is composed, the logging core decides if this log record is going to be processed in sinks. This is called filtering. There are two layers of filtering available: the global filtering is applied first within the logging core itself and allows quickly wiping away unneeded log records; the sink-specific filtering is applied second, for each sink separately. The sink-specific filtering allows directing log records to particular sinks. Note that at this point it is not significant which logging source emitted the record, the filtering relies solely on the set of attribute values attached to the record.
It must be mentioned that for a given log record filtering is performed only once. Obviously, only those attribute values attached to the record before filtering starts can participate in filtering. Some attribute values, like log record message, are typically attached to the record after the filtering is done; such values cannot be used in filters, they can only be used by formatters and sinks themselves.
If a log record passes filtering for at least one sink the record is considered to be consumable. If the sink supports formatted output, this is the point when log message formatting takes place. The formatted message along with the composed set of attribute values is passed to the sink that accepted the record. Note that formatting is performed on the per-sink basis so that each sink can output log records in its own specific format.
As you may have noticed on the figure above, sinks consist of two parts: the frontend and the backend. This division is made in order to extract the common functionality of sinks, such as filtering, formatting and thread synchronization, into separate entities (frontends). Sink frontends are provided by the library, most likely users won't have to re-implement them. Backends, on the other hand, are one of the most likely places for extending the library. It is sink backends that do the actual processing of log records. There can be a sink that stores log records into a file; there can be a sink that sends log records over the network to the remote log processing node; there can be the aforementioned sink that puts record messages into tool-tip notifications - you name it. The most commonly used sink backends are already provided by the library.
Along with the primary facilities described above, the library provides a wide variety of auxiliary tools, such as attributes, support for formatters and filters, represented as lambda expressions, and even basic helpers for the library initialization. You will find their description in the Detailed features description section. However, for new users it is recommended to start discovering the library from the Tutorial section.