 Boost
C++ Libraries
Boost
C++ Libraries
...one of the most highly
regarded and expertly designed C++ library projects in the
world.
— Herb Sutter and Andrei
Alexandrescu, C++
Coding Standards
Boost
C++ Libraries
...one of the most highly
regarded and expertly designed C++ library projects in the
world.
— Herb Sutter and Andrei
Alexandrescu, C++
Coding Standards


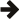
Multi-function operations allow running operations as a set of separate steps, which gives you better control over execution. They work by splitting some of the reads and writes into several function calls. You can use multi-function operations to execute text queries and prepared statements.
To make a good use of multi-function operations, you should have a basic understanding of the underlying protocol.
The protocol uses messages to communicate. These are delimited by headers containing the message length. All operations are initiated by the client, by sending a single request message, to which the server responds with a set of response messages.
The diagram below shows the message exchange between client and server for text queries and statement executions. Each arrow represents a message.
The message exchange is similar for text queries and prepared statements. The wire format varies, but the semantics are the same.
There are two separate cases:
results::meta
and execution_state::meta,
and are necessary to parse the rows.
last_insert_id
and affected_rows.
connection::query
and connection::execute_statement
handle the full message exchange. In contrast, connection::start_query
and connection::start_statement_execution
will not read the rows, if any.
Some takeaways:
Given the following setup:
results result; conn.query( R"%( CREATE TEMPORARY TABLE posts ( id INT PRIMARY KEY AUTO_INCREMENT, title VARCHAR (256), body TEXT ) )%", result ); conn.query( R"%( INSERT INTO posts (title, body) VALUES ('Post 1', 'A very long post body'), ('Post 2', 'An even longer post body') )%", result ); statement stmt = conn.prepare_statement("SELECT title, body FROM posts");
You can start a multi-function operation using connection::start_query
or connection::start_statement_execution:
|
Text queries |
Prepared statements |
|---|---|
execution_state st; conn.start_query("SELECT title, body FROM posts", st); |
execution_state st; conn.start_statement_execution( stmt, std::make_tuple(), // The statement has no params, so an empty tuple is passed st ); |
Once the operation has been started, you must
read all the generated rows by calling connection::read_some_rows,
which will return a batch of an unspecified size.
This is the typical use of read_some_rows:
// st.complete() returns true once the OK packet is received while (!st.complete()) { // row_batch will be valid until conn performs the next network operation rows_view row_batch = conn.read_some_rows(st); for (row_view post : row_batch) { // Process post as required std::cout << "Title:" << post.at(0) << std::endl; } }
Some remarks:
read_some_rows
will return at least one, but may return more.
execution_state::complete
returns true after we've read
the final OK packet for this operation.
row_batch may
or may not be empty, depending on the number of rows and their size.
read_some_rows
after reading the final OK packet returns an empty batch.
read_some_rows returns a rows_view
object pointing into the connection's internal buffers. This view is valid
until the connection performs any other operation involving a network transfer.
Note that there is no need to distinguish between case 1 and case 2 in the diagram above in our code, as reading rows for a complete operation is well defined.
You can access metadata at any point, using execution_state::meta.
This function returns a collection of metadata
objects. There is one object for each column retrieved by the SQL query, and
in the same order as in the query. You can find a bunch of useful information
in this object, like the column name, its type, whether it's a key or not,
and so on.
You can access OK packet data using functions like execution_state::last_insert_id
and execution_state::affected_rows.
As this information is contained in the OK packet, these
functions have st.complete() == true as precondition.
To properly understand read_some_rows,
we need to know that every connection
owns an internal read buffer, where packets
sent by the server are stored. It is a single, flat buffer, and you can configure
its initial size when creating a connection,
passing a buffer_params
object as the first argument to connection's
constructor. The read buffer may be grown under certain circumstances to accomodate
large messages.
read_some_rows gets the maximum
number of rows that fit in the read buffer (without growing it) performing
a single read_some operation
on the stream (or using cached data). If there are rows to read, read_some_rows guarantees to read at least
one. This means that, if doing what we described yields no rows (e.g. because
of a large row that doesn't fit into the read buffer), read_some_rows
will grow the buffer or perform more reads until at least one row has been
read.
If you want to get the most of read_some_rows,
customize the initial read buffer size to maximize the number of rows that
each batch retrieves.