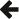Multi-function operations allow running operations as a set of separate steps,
which gives you better control over execution. They work by splitting some
of the reads and writes into several function calls.
You can use multi-function operations to execute text queries and prepared
statements, and through the dynamic or the static interface.
To make a good use of multi-function operations, you should have a basic understanding
of the underlying protocol.
The protocol uses messages to communicate. These are delimited
by headers containing the message length. All operations are initiated by the
client, by sending a single request message, to which
the server responds with a set of response messages.
The diagram below shows the message exchange between client and server for
text queries and statement executions. Each arrow represents a message.
There are two separate cases:
If your query retrieved at least one column (even if no rows were generated),
we're in case 1. The server sends:
An initial packet informing that the query executed correctly, and
that we're in case 1.
Some metadata packets describing the columns that the query retrieved.
These become available to the user and are necessary to parse the
rows.
The actual rows.
An OK packet, which marks the end of the resultset and contains information
like last_insert_id
and affected_rows.
If your query didn't retrieve any column, we're in case 2.
The server will just send an OK packet, with the same information as in
case 1.
The distinction between single-function and multi-function operations exists
only in the client. The wire messages exchanged by both are the same.
There is no way to tell how many rows a resultset has upfront. You need
to read row by row until you find the OK packet marking the end of the
resultset.
When the server processes the request message, it
sends all the response messages immediately. These responses
will be waiting in the client to be read. If you don't read all
of them, subsequent operations will mistakenly read them as their response,
causing packet mismatches. Be careful and don't let this happen!
execution_state
is the main class for the dynamic interface in multi-function operations. An
execution state holds information required to progress the execution operation,
like metadata (required to parse the rows) and protocol state. Contrary to
results, it doesn't contain
the rows.
Given the following table definition:
constchar*table_definition=R"%(
CREATE TEMPORARY TABLE posts (
id INT PRIMARY KEY AUTO_INCREMENT,
title VARCHAR (256) NOT NULL,
body TEXT NOT NULL
)
)%";
// st will hold information about the operation being executed.// It must be passed to any successive operations for this executionexecution_statest;// Sends the query and reads response and meta, but not the rowsconn.start_execution("SELECT title, body FROM posts",st);
We now must read all the generated rows by
calling connection::read_some_rows,
which will return a batch of an unspecified size:
// st.complete() returns true once the OK packet is receivedwhile(!st.complete()){// row_batch will be valid until conn performs the next network operationrows_viewrow_batch=conn.read_some_rows(st);for(row_viewpost:row_batch){// Process post as requiredstd::cout<<"Title:"<<post.at(0)<<std::endl;}}
Some remarks:
If there are rows to be read, read_some_rows
will return at least one, but may return more.
The final row_batch may
or may not be empty, depending on the number of rows and their size.
Calling read_some_rows
after reading the final OK packet returns an empty batch.
read_some_rows returns a rows_view
object pointing into the connection's internal buffer. This view is valid until
the connection performs any other operation involving a network transfer.
Note that there is no need to distinguish between case 1
and case 2 in the diagram above in our code, as reading
rows for a complete operation is well defined.
The mechanics are similar to what's been exposed above. The static interface
uses static_execution_state
to carry state. As with static_results,
we must define and pass a type describing our rows:
// We can use a plain struct with ints and strings to describe our rows.// This must be placed at the namespace levelstructpost{intid;std::stringtitle;std::stringbody;};// We use BOOST_DESCRIBE_STRUCT to add reflection capabilities to post.// We must list all the fields that should be populated by Boost.MySQLBOOST_DESCRIBE_STRUCT(post,(),(id,title,body))
// st will hold information about the operation being executed.// It must be passed to any successive operations for this executionstatic_execution_state<post>st;// Sends the query and reads response and meta, but not the rows.// If there is any schema mismatch between the declared row type and// what the server returned, start_execution will detect it and failconn.start_execution("SELECT id, title, body FROM posts",st);
// storage will be filled with the read rows. You can use any other contiguous range.std::array<post,20>posts;// st.complete() returns true once the OK packet is receivedwhile(!st.complete()){std::size_tread_rows=conn.read_some_rows(st,boost::span<post>(posts));for(constpost&p:boost::span<post>(posts.data(),read_rows)){// Process post as requiredstd::cout<<"Title "<<p.title<<std::endl;}}
Some remarks:
static_execution_state
doesn't store rows anyhow. It uses the row types passed as template parameters
to validate the metadata returned by the server, and ensure it is compatible
with the C++ data structures that will be used with read_some_rows.
We must pass read_some_rows
a boost::span of the appropriate row type. We've
used std::array to place rows on the stack, but
you can use any other contiguous range.
read_some_rows returns
the number of read rows. At maximum, this will be the size of the span,
but there may be less, depending on row and network buffer sizes.
If there are rows to be read, read_some_rows
will return at least one, but may return more.
You can access OK packet data using functions like last_insert_id
and affected_rows
in both execution_state and
static_execution_state. As
this information is contained in the OK packet, it can
only be accessed once the complete
function returns true.
When using operations that return more than one resultset (e.g. when calling
stored procedures), the protocol is slightly more complex:
The message exchange is as follows:
A single execution request is sent to the server.
The server sends a first resultset, as in the single resultset case. The
OK packet contains a flag indicating that another resultset follows.
Another resultset is sent, with the same structure as the previous one.
The process is repeated until an OK packet indicates that no more resultsets
follow.
For example, given the following stored procedure:
CREATE PROCEDURE get_company(IN pin_company_id CHAR(10))
BEGIN
START TRANSACTION READ ONLY;
SELECT id, name, tax_id FROM company WHERE id = pin_company_id;
SELECT first_name, last_name, salary FROM employee WHERE company_id = pin_company_id;
COMMIT;
END
We can write:
Dynamic interface
Static interface
// Get the company ID to retrieve, possibly from the userstd::stringcompany_id=get_company_id();// Call the procedureexecution_statest;statementstmt=conn.prepare_statement("CALL get_employees(?)");conn.start_execution(stmt.bind(company_id),st);// The above code will generate 3 resultsets// Read the 1st one, which contains the matched companieswhile(st.should_read_rows()){rows_viewcompany_batch=conn.read_some_rows(st);// Use the retrieved companies as requiredfor(row_viewcompany:company_batch){std::cout<<"Company: "<<company.at(1).as_string()<<"\n";}}// Move on to the 2nd one, containing the employees for these companiesconn.read_resultset_head(st);while(st.should_read_rows()){rows_viewemployee_batch=conn.read_some_rows(st);// Use the retrieved employees as requiredfor(row_viewemployee:employee_batch){std::cout<<"Employee "<<employee.at(0).as_string()<<" "<<employee.at(1).as_string()<<"\n";}}// The last one is an empty resultset containing information about the// CALL statement itself. We're not interested in thisconn.read_resultset_head(st);assert(st.complete());
// Get the company ID to retrieve, possibly from the userstd::stringcompany_id=get_company_id();// Our procedure generates three resultsets. We must pass each row type// to static_execution_state as template parametersusingempty=std::tuple<>;static_execution_state<company,employee,empty>st;// Call the procedurestatementstmt=conn.prepare_statement("CALL get_employees(?)");conn.start_execution(stmt.bind(company_id),st);// Read the 1st one, which contains the matched companiesstd::array<company,5>companies;while(st.should_read_rows()){std::size_tread_rows=conn.read_some_rows(st,boost::span<company>(companies));// Use the retrieved companies as requiredfor(constcompany&c:boost::span<company>(companies.data(),read_rows)){std::cout<<"Company: "<<c.name<<"\n";}}// Move on to the 2nd one, containing the employees for these companiesconn.read_resultset_head(st);std::array<employee,20>employees;while(st.should_read_rows()){std::size_tread_rows=conn.read_some_rows(st,boost::span<employee>(employees));// Use the retrieved companies as requiredfor(constemployee&emp:boost::span<employee>(employees.data(),read_rows)){std::cout<<"Employee "<<emp.first_name<<" "<<emp.last_name<<"\n";}}// The last one is an empty resultset containing information about the// CALL statement itself. We're not interested in thisconn.read_resultset_head(st);assert(st.complete());
Note that we're using should_read_rows
instead of complete
as our loop termination condition. complete() returns true when all the resultsets have
been read, while should_read_rows() will return false once an individual result
has been fully read.
When using the static interface with multi-function operations, not all schema
mismatches can be found by the start_execution
function, since not all the information is available at this point. Errors
may be reported by read_some_rows
and read_resultset_head, too.
Overall, the same checks are performed as when using connection::execute,
but at different points in time.
execution_state and static_execution_state can be seen as state
machines with four states. Each state describes which reading function should
be invoked next:
For multi-function operations, you may also access OK packet data ever time
a resultset has completely been read, i.e. when should_read_head
returns true.
This example shows this
general case. It uses multi-queries to run an arbitrary SQL script file.
To properly understand read_some_rows,
we need to know that every connection
owns an internal buffer, where packets sent
by the server are stored. It is a single, flat buffer, and you can configure
its initial size when creating a connection,
passing a buffer_params
object as the first argument to connection's
constructor. The read buffer may be grown under certain circumstances to accommodate
large messages.
read_some_rows gets the maximum
number of rows that fit in the internal buffer (without growing it) performing
a single read_some operation
on the stream (or using cached data). If there are rows to read, read_some_rows guarantees to read at least
one. This means that, if doing what we described yields no rows (e.g. because
of a large row that doesn't fit into the buffer), read_some_rows
will grow the buffer or perform more reads until at least one row has been
read. If you're using the static interface, the number of read rows is limited
by the size of span you passed, too.
If you want to get the most of read_some_rows,
customize the initial buffer size to maximize the number of rows that each
batch retrieves.
 Boost
C++ Libraries
Boost
C++ Libraries