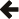Lexical scanning is the process of analyzing the stream of input characters
and separating it into strings called tokens, separated by whitespace. Most
compiler texts start here, and devote several chapters to discussing various
ways to build scanners. Spirit.Lex is a library built
to take care of the complexities of creating a lexer for your grammar (in
this documentation we will use the terms 'lexical analyzer', 'lexer' and
'scanner' interchangably). All that is needed to create a lexer is to know
the set of patterns describing the different tokens you want to recognize
in the input. To make this a bit more formal, here are some definitions:
-
A token is a sequence of consecutive characters having a collective meaning.
Tokens may have attributes specific to the token type, carrying additional
information about the matched character sequence.
-
A pattern is a rule expressed as a regular expression and describing how
a particular token can be formed. For example,
[A-Za-z][A-Za-z_0-9]*
is a pattern for a rule matching C++ identifiers.
-
Characters between tokens are called whitespace; these include spaces,
tabs, newlines, and formfeeds. Many people also count comments as whitespace,
though since some tools such as lint look at comments, this method is not
perfect.
Typically, lexical scanning is done in a separate module from the parser,
feeding the parser with a stream of input tokens only. Theoretically it is
not necessary implement this separation as in the end there is only one set
of syntactical rules defining the language, so in theory we could write the
whole parser in one module. In fact, Spirit.Qi allows
you to write parsers without using a lexer, parsing the input character stream
directly, and for the most part this is the way Spirit
has been used since its invention.
However, this separation has both practical and theoretical basis, and proves
to be very useful in practical applications. In 1956, Noam Chomsky defined
the "Chomsky Hierarchy" of grammars:
-
Type 0: Unrestricted grammars (e.g., natural languages)
-
Type 1: Context-Sensitive grammars
-
Type 2: Context-Free grammars
-
Type 3: Regular grammars
The complexity of these grammars increases from regular grammars being the
simplest to unrestricted grammars being the most complex. Similarly, the
complexity of pattern recognition for these grammars increases. Although,
a few features of some programming languages (such as C++) are Type 1, fortunately
for the most part programming languages can be described using only the Types
2 and 3. The neat part about these two types is that they are well known
and the ways to parse them are well understood. It has been shown that any
regular grammar can be parsed using a state machine (finite automaton). Similarly,
context-free grammars can always be parsed using a push-down automaton (essentially
a state machine augmented by a stack).
In real programming languages and practical grammars, the parts that can
be handled as regular expressions tend to be the lower-level pieces, such
as the definition of an identifier or of an integer value:
letter := [a-zA-Z]
digit := [0-9]
identifier := letter [ letter | digit ]*
integer := digit+
Higher level parts of practical grammars tend to be more complex and can't
be implemented using plain regular expressions. We need to store information
on the built-in hardware stack while recursing the grammar hierarchy, and
that is the preferred approach used for top-down parsing. Since it takes
a different kind of abstract machine to parse the two types of grammars,
it proved to be efficient to separate the lexical scanner into a separate
module which is built around the idea of a state machine. The goal here is
to use the simplest parsing technique needed for the job.
Another, more practical, reason for separating the scanner from the parser
is the need for backtracking during parsing. The input data is a stream of
characters, which is often thought to be processed left to right without
any backtracking. Unfortunately, in practice most of the time that isn't
possible. Almost every language has certain keywords such as IF, FOR, and
WHILE. The decision if a certain character sequence actually comprises a
keyword or just an identifier often can be made only after seeing the first
delimiter after it. In fact, this makes the process
backtracking, since we need to store the string long enough to be able to
make the decision. The same is true for more coarse grained language features
such as nested IF/ELSE statements, where the decision about to which IF belongs
the last ELSE statement can be made only after seeing the whole construct.
So the structure of a conventional compiler often involves splitting up the
functions of the lower-level and higher-level parsing. The lexical scanner
deals with things at the character level, collecting characters into strings,
converting character sequence into different representations as integers,
etc., and passing them along to the parser proper as indivisible tokens.
It's also considered normal to let the scanner do additional jobs, such as
identifying keywords, storing identifiers in tables, etc.
Now, Spirit follows this
structure, where Spirit.Lex can be used to implement
state machine based recognizers, while Spirit.Qi can
be used to build recognizers for context free grammars. Since both modules
are seemlessly integrated with each other and with the C++ target language
it is even possible to use the provided functionality to build more complex
grammar recognizers.
The advantage of using Spirit.Lex to create the lexical
analyzer over using more traditional tools such as Flex
is its carefully crafted integration with the Spirit
library and the C++ host language. You don't need any external tools to generate
the code, your lexer will be perfectly integrated with the rest of your program,
making it possible to freely access any context information and data structure.
Since the C++ compiler sees all the code, it will generate optimal code no
matter what configuration options have been chosen by the user. Spirit.Lex
gives you the vast majority of features you could get from a similar Flex program without the need
to leave C++ as a host language:
-
The definition of tokens is done using regular expressions (patterns)
-
The token definitions can refer to special substitution strings (pattern
macros) simplifying pattern definitions
-
The generated lexical scanner may have multiple start states
-
It is possible to attach code to any of the token definitions; this code
gets executed whenever the corresponding token pattern has been matched
Even if it is possible to use Spirit.Lex to generate
C++ code representing the lexical analyzer (we will refer to that as the
static model, described in more detail in the section
The Static
Model) - a model very similar to the way Flex
operates - we will mainly focus on the opposite, the dynamic
model. You can directly integrate the token definitions into your C++ program,
building the lexical analyzer dynamically at runtime. The dynamic model is
something not supported by Flex
or other lexical scanner generators (such as re2c,
Ragel, etc.).
This dynamic flexibility allows you to speed up the development of your application.
The figure below shows a high level
overview of how the Spirit.Lex library might be used
in an application. Spirit.Lex allows to create lexical
analyzers based on patterns. These patterns are regular expression based
rules used to define the different tokens to be recognized in the character
input sequence. The input sequence is expected to be provided to the lexical
analyzer as an arbitrary standard forward iterator. The lexical analyzer
itself exposes a standard forward iterator as well. The difference here is
that the exposed iterator provides access to the token sequence instead of
to the character sequence. The tokens in this sequence are constructed on
the fly by analyzing the underlying character sequence and matching this
to the patterns as defined by the application.
 Boost
C++ Libraries
Boost
C++ Libraries